| Excerpt |
|---|
Planning a sprint in JIRA Agile involves assigning issues. You want to spread the load fairly, not overburdening or underburdening workers. To complicate matters, some issues take longer than others (with more Story Points or greater Time Estimate), and the capacity of each worker varies per week, as they may have time off or other responsibilities. To meet this planning need in a simple way, we have developed the Sprint Capacity Report, a Confluence-based report that queries JIRA, showing issues grouped per assignee, showing time estimates vs. assignee capacity. |
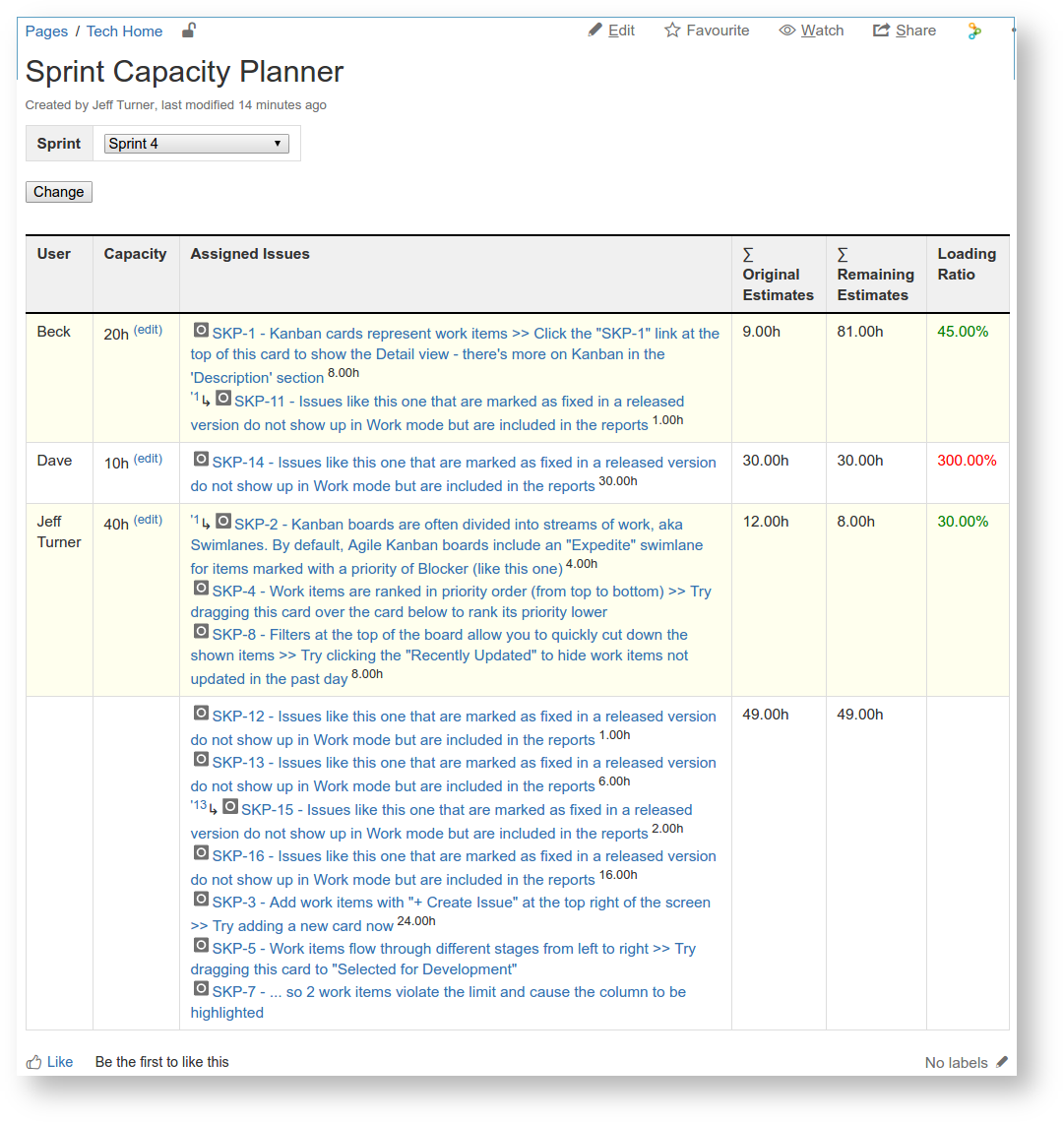
The drop-down list selects the Sprint whose issues/assignees are shown. In this example we see, for instance, that Dave is able to work 10 hours this sprint, is assigned one issue (SKP-14), which is estimated to take 30h, so Dave would be at 300% capacity unless we change things. There are 49 hours' worth of unassigned issues.
...
The report is implemented as a giant parametrized SQL query running within a Confluence page, with the SQL running against the JIRA database. The only dependency is the commercial SQL for Confluence plugin. Advanced users are encouraged to follow and understand the implementation described below. Advanced users who know the value of their own time are encouraged to [contact
Install the SQL plugin
First install the SQL for Confluence plugin. This plugin is indispensable for Confluence, much like ScriptRunner is for JIRA.
...
To create this page, install the Confluence Source Editor plugin, save and re-edit your Sprint Capacity Planner page, click the <> in the top-right, and paste in the contents of sprintcapacityplanner.xhtml
Conclusion
The end result is a Confluence page where:
- A drop-down list of Sprints is auto-generated by querying the JIRA database.
- When the user clicks 'Change', the chosen sprint's ID is re-sent to the page as a URL parameter, which is extracted by the Param macro.
- The sprint param is embedded in a large SQL query, which queries the JIRA database to extract relevant sprint data
Please contact us if you have any comments or questions.