Planning a sprint in JIRA Agile involves assigning issues. You want to spread the load fairly, not overburdening or underburdening workers. To complicate matters, some issues take longer than others (with more Story Points or greater Time Estimate), and the capacity of each worker varies per week, as they may have time off or other responsibilities. To meet this planning need in a simple way, we have developed the Sprint Capacity Report, a Confluence-based report that queries JIRA, showing issues grouped per assignee, showing time estimates vs. assignee capacity.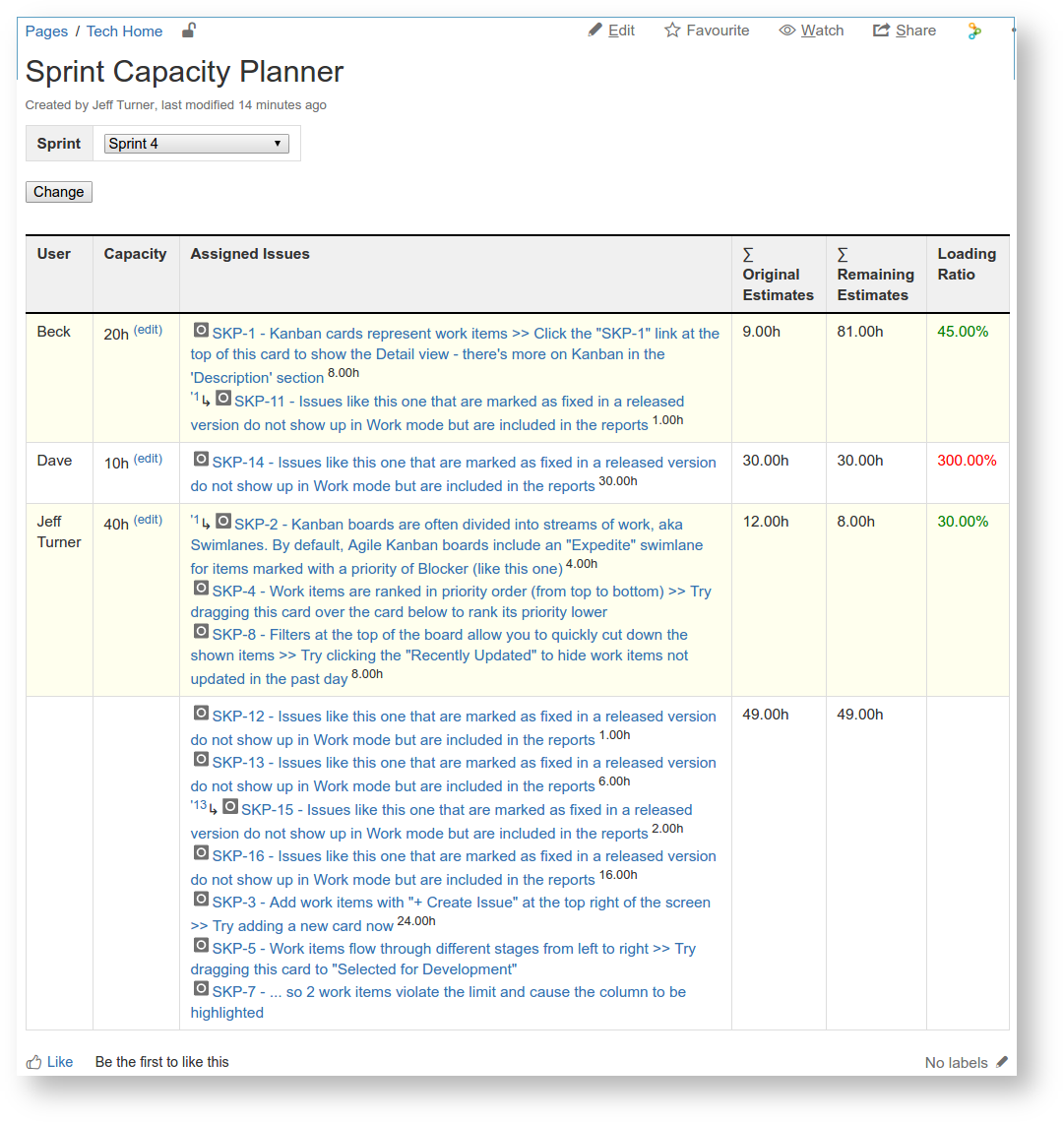
The drop-down list selects the Sprint whose issues/assignees are shown. In this example we see, for instance, that Dave is able to work 10 hours this sprint, is assigned one issue (SKP-14), which is estimated to take 30h, so Dave would be at 300% capacity unless we change things. There are 49 hours' worth of unassigned issues.
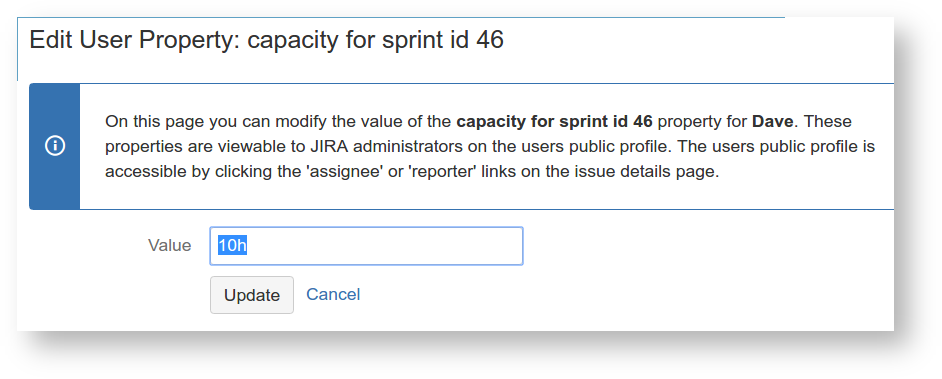
User capacities are stored as user properties in JIRA. E.g. clicking 'Edit' in the Capacity column for Dave brings up:
Implementation
The report is implemented as a giant parametrized SQL query running within a Confluence page, with the SQL running against the JIRA database.
Install the SQL plugin
First install the SQL for Confluence plugin. This plugin is indispensable for Confluence, much like ScriptRunner is for JIRA.
Define a Datasource to access JIRA
First we need to allow Confluence access to our JIRA database, via a datasource configured in Confluence's server.xml file, usually found at /opt/atlassian/confluence/conf/server.xml. This block should be inserted nested within the <Context>, just below the line <Manager pathname="" />.
<Resource name="jdbc/JiraDS" auth="Container" type="javax.sql.DataSource"
username="redradish_jira"
password="s3cret"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost/redradish_jira"
maxActive="20"
validationQuery="select 1"/>
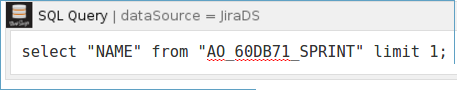
Restart Confluence. Afterwards, a simple query like SELECT "NAME" FROM "AO_60DB71_SPRINT" against the JiraDS database should work.
Sprints drop-down
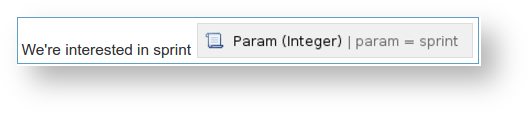
We need to prompt the user for the Sprint they wish to review.

This drop-down is implemented as a Confluence "user macro". See the JIRA Sprint select-list macro for the implementation.
Once implemented, insert the macro in your page, parametrized with the JIRA datasource name ( JiraDS ):

Define a Param user macro
When the user clicks a sprint from the list above, the page reloads with a sprint=xyz parameter, where xyz is the internal Sprint ID. Define the Param (Integer) macro, as specified at HTTP Parameter Macros, and verify that it works.
Make a dynamic SQL wrapper macro
We now know what sprint ID we're interested in, and could potentially query the right database table with the SQL macro, but unfortunately the SQL Query macro won't allow nesting of our Param (Integer) macro. See Allow macro content inside any other macro for a SQL wrapper macro that gets around this. We can now do:

Query SQL
Create a page in Confluence called Sprint Capacity Planner, whose contents is a Sprints Dropdown macro, and then a SQL Dynamically Generated macro wrapping a Param (Integer):
To create this page, install the Confluence Source Editor plugin, save and re-edit your Sprint Capacity Planner page, click the <> in the top-right, and paste in the contents of sprintcapacityplanner.xhtml