What a barrel of laughs this Jira 8.20.1 upgrade is proving to be! After yesterday's Jira 8.20.x gotcha: lost notifications, today's problem is that autocomplete on the 'Assignee' field is breaking:
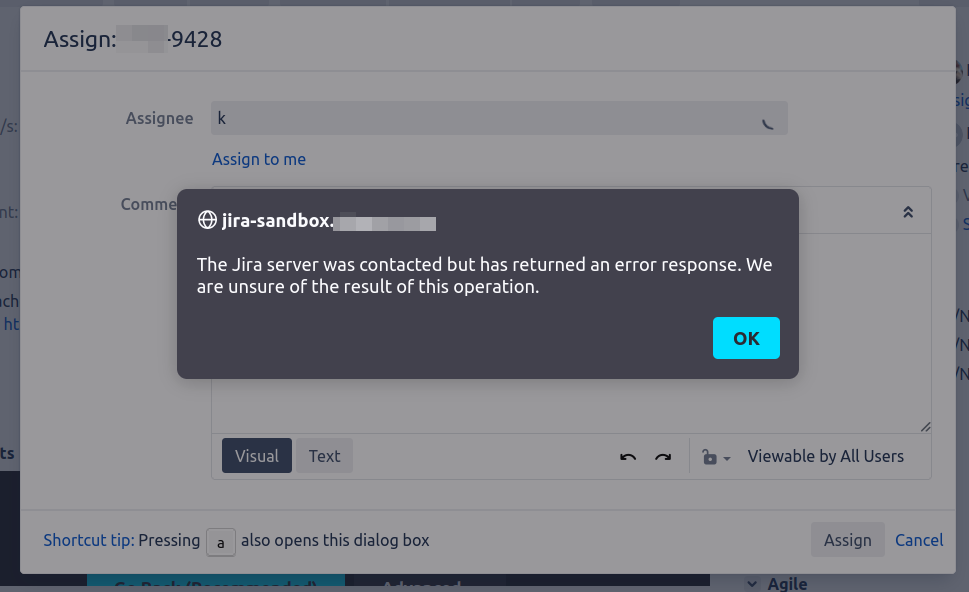
But only for some users on some projects, which is why the problem wasn't picked up in sandbox testing.
Lovely source code
There is at least a stacktrace in atlassian-jira.log:
Caused by: java.lang.NullPointerException
at java.base/java.util.Comparator.lambda$comparing$77a9974f$1(Comparator.java:469)
at java.base/java.util.Comparator.lambda$thenComparing$36697e65$1(Comparator.java:216)
at java.base/java.util.TreeMap.put(TreeMap.java:550)
at java.base/java.util.TreeSet.add(TreeSet.java:255)
at java.base/java.util.AbstractCollection.addAll(AbstractCollection.java:352)
at com.atlassian.jira.permission.DefaultIssueUserSearchManager.findTopUsersWithPermissionInIssue(DefaultIssueUserSearchManager.java:253)
at com.atlassian.jira.permission.DefaultIssueUserSearchManager.findTopUsersInternal(DefaultIssueUserSearchManager.java:168)
at com.atlassian.jira.permission.DefaultIssueUserSearchManager.findTopAssignableUsers(DefaultIssueUserSearchManager.java:115)
at com.atlassian.jira.bc.user.search.DefaultUserPickerSearchService.findTopAssignableUsers(DefaultUserPickerSearchService.java:326)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
This is the point where I'm glad I work with Atlassian products, because although they are sometimes buggy and broken, the source code is available to licensees. So we can debug this problem.
The code in question is adding a bunch of user objects to a collection object called result:

The result field is defined a bit higher, as a collection object of type TreeSet, and the constructor is passed a Comparator used to determine the sort order. Here we see the Comparator is using getLowerDisplayName() and getLowerUserName() :

So we should be on the lookout of null values of those fields. Sure enough, if we hook up a debugger and inspect the UserDTOs starting with letter 'k', we have one object with a null lowerDisplayName field:
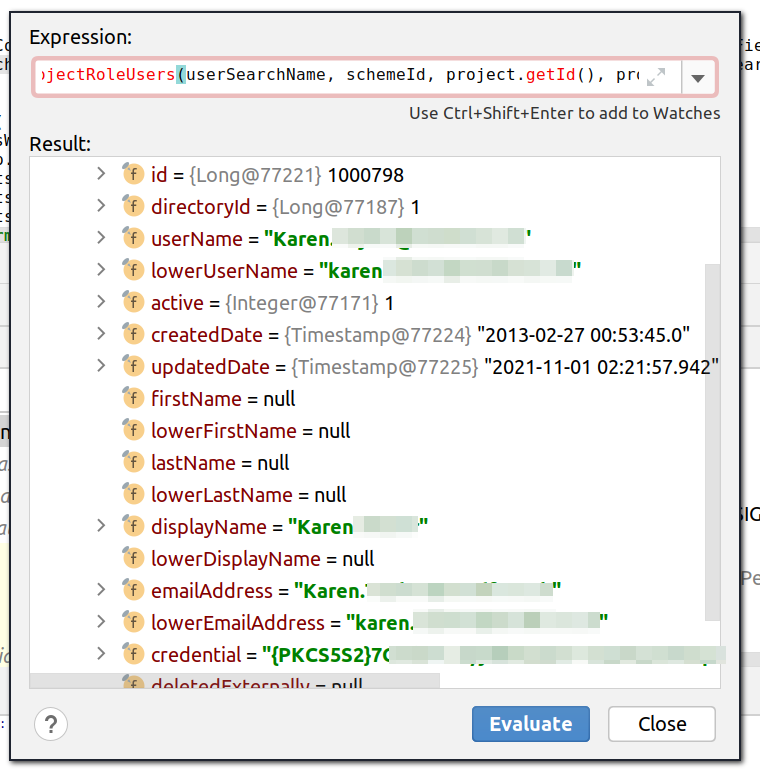
The class involved, DefaultIssueUserSearchManager, appears to be new in Jira 8.19.x, and clearly wasn't tested with much real-world data.
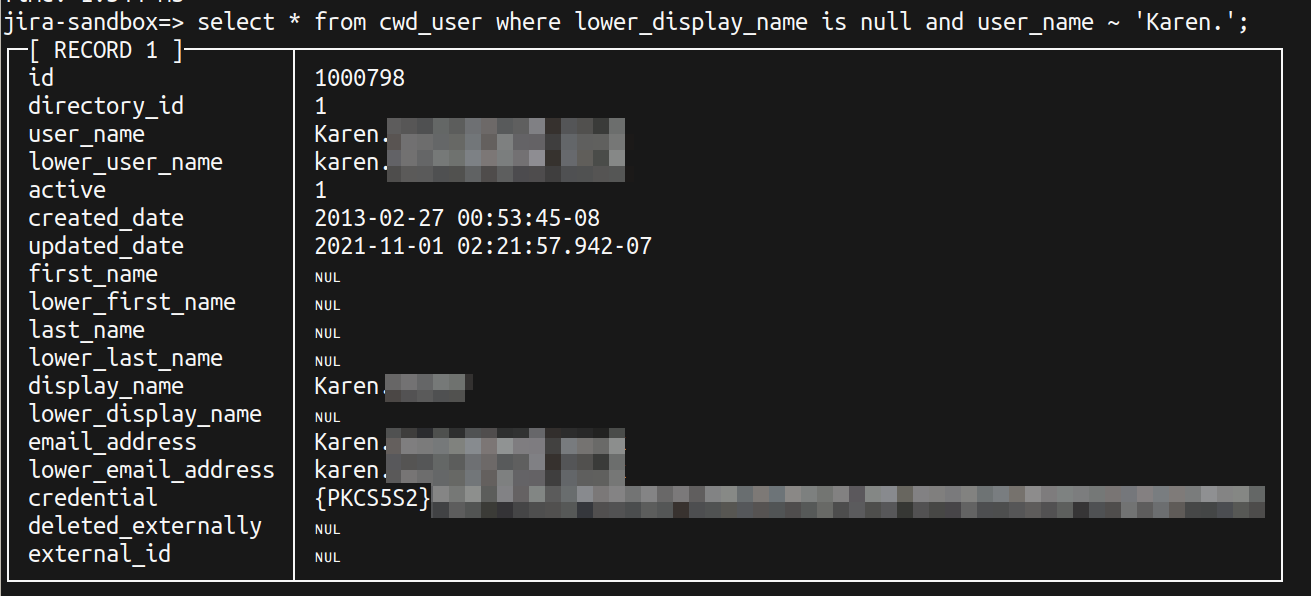
Why is the user data missing fields?
I don't know why those fields are null. It it only the case in a small subset of user accounts (80 of 3700 accounts), all created before May 2017.
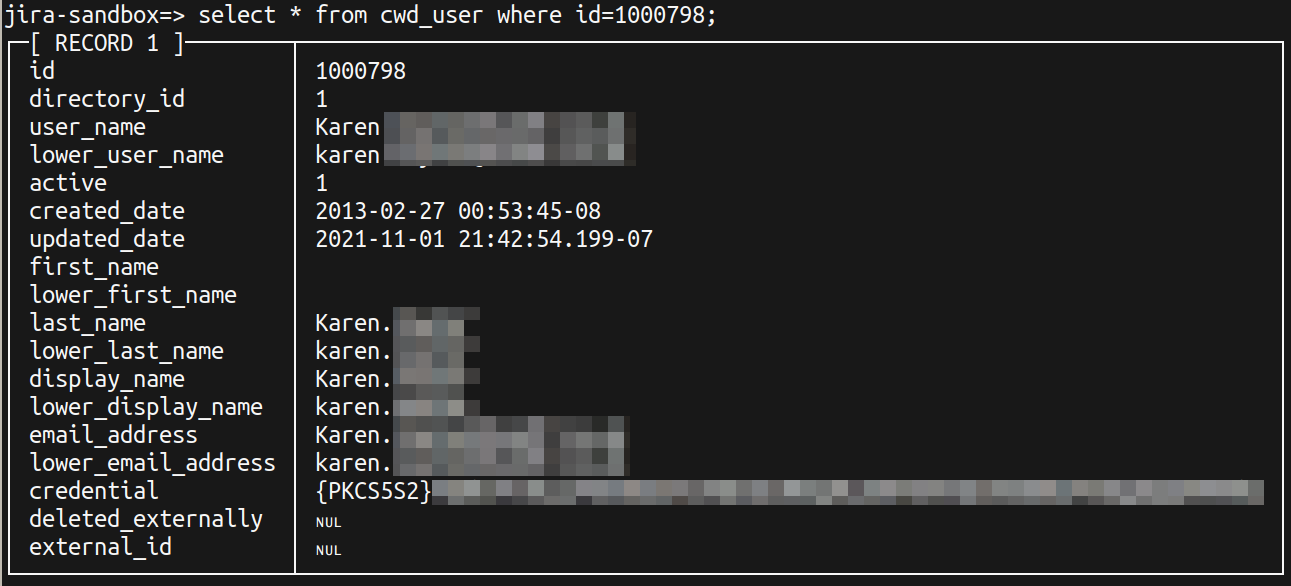
If I find the user's account in the Jira administration section, click 'Edit Details' and simply save, then all the null fields suddenly get values:
| Before | After |
|---|---|
| |
Fixing with SQL
So let's fix up the null fields. Here is some Postgres-flavoured SQL that makes use of the fact that display_name is generally of the form "Firstname Lastname", with fallback to just blatting display_name into first_name and last_name.
begin; update cwd_user set lower_display_name=lower(display_name) where lower_display_name is null; update cwd_user set first_name=split_part(display_name, ' ', 1) where first_name is null and display_name~'^[^ ]+ [^ ]+$'; update cwd_user set last_name=split_part(display_name, ' ', 2) where last_name is null and display_name~'^[^ ]+ [^ ]+$'; update cwd_user set first_name=display_name where first_name is null and display_name!~'^[^ ]+ [^ ]+$' ; update cwd_user set last_name=display_name where last_name is null and display_name!~'^[^ ]+ [^ ]+$' ; update cwd_user set lower_first_name=lower(first_name) where lower_first_name is null; update cwd_user set lower_last_name=lower(last_name) where lower_last_name is null; commit;
The nice thing about cwd_ tables is they aren't cached (AFAIK), so you don't need to restart. Commit the changes to the database, and your autocomplete should start working.
Confluence user macros put power in the hands of administrators to create custom macros utilizing the full Confluence API. They are one of Confluence Server's best features, analogous to Jira ScriptRunner 'Script Fields'. I've written a number of them over time.
However there is a strong trend in tech for Big Tech to take power away from end users in the name of security. Thus, if you upgrade to Confluence 7.9+, you may find your more interesting User Macros have broken:

A common trick in writing User Macros is to get a class via reflection with a construct like:
#set($df = $action.getDateFormatter())
#set($now = $action.getClass().forName("java.util.Date").newInstance())
In Confluence 7.x this is no longer permitted, in the name of security. See forum post:
The fix as described works, namely to remove the restrictions on java.lang.reflect , java.lang.Class and java.lang.ClassLoader :
diff --git a/confluence/WEB-INF/classes/velocity.properties b/confluence/WEB-INF/classes/velocity.properties --- a/confluence/WEB-INF/classes/velocity.properties +++ b/confluence/WEB-INF/classes/velocity.properties @@ -163,7 +163,7 @@ velocimacro.max.depth=-1 # https://extranet.atlassian.com/display/CSPF/Restrict+packages+and+classes+usage+from+velocity+files # ---------------------------------------------------------------------------- -introspector.restrict.packages = java.lang.reflect,\ +introspector.restrict.packages = \ com.atlassian.cache,\ com.atlassian.confluence.util.http,\ com.atlassian.failurecache,\ @@ -230,8 +230,7 @@ org.springframework.util.concurrent,\ org.quartz,\ oshi -introspector.restrict.classes = java.lang.Class,\ -java.lang.ClassLoader,\ +introspector.restrict.classes = \ java.lang.Compiler,\ java.lang.InheritableThreadLocal,\ java.lang.Package,\
On Atlassian announced the future discontinuation of its Server products in favour of the Cloud equivalents.
The response has been overwhelmingly negative on Atlassian's forums [1, 2] and publicly [3, 4, 5, 6]. Objections are in roughly 3 categories:
- Some organizations unable to move to Cloud due to:
- security / privacy concerns
- regulatory concerns (e.g. server hosting jurisdiction).
- existing deep integrations with internal apps/data
- Dislike of Atlassian's Cloud products, for being:
- 'dumbed down'
- slow
- inflexible (fewer, weaker add-ons)
- unstable (regular UI changes; third-party app stability)
- Price increases
- Cloud is relatively unaffordable. Cost increasing 3x to 5x vs. Server renewals.
I too am deeply disappointed. I have long believed the Server products are simply better than Cloud equivalents. Red Radish Consulting's schtick has always been helping companies getting the most out of Server products; so what happens now they're going away? Atlassian are killing the better product to force people onto their higher revenue product, to the detriment of everyone.
Isn't this what happens when good companies take VC money: they sell out?
It would be so easy to jump on the hate and cynicism bandwagon. But let's consider:
- No company has an obligation to support a particular piece of software forever. We can disagree with Atlassian's choice of direction, but ultimately it's their software. Let's gracefully accept it and move on. Any stronger emotion is probably the result of a misplaced sense of entitlement.
- We were warned. Atlassian have been very vocal for years that they regard Cloud as the future. Development in Server has been stagnant for the last 10 years.
- We should assume good faith. I truly believe Mike and Scott want to do what's best for their customers. This is not a cynical cash grab under VC pressure. I was in the room when Atlassian's Values were hashed out: they truly believe in "don't f**k the customer". Mike and Scott believe that:
- Cloud is a fundamentally better way of delivering software
- By focusing on Cloud, Atlassian can build better Cloud products
- Some short term pain now will result in more, happier customers in the medium to long term.
There are counterarguments to all these points. 3 years' notice is not particularly generous for a 17 year old product. While it's true we were warned, most people expected a dignified retirement for Server rather than being taken out the back and shot.
As for Atlassian's strategy, it hinges on the theory that killing Server will somehow make Cloud a better product. This doesn't fly with me for two reasons.
Firstly, Atlassian have had 10 years and all the money they could want to make Cloud good. They've frittered it all away chasing UX fads and creating dumbed-down 'next-gen' interfaces. Shutting down Server will let Atlassian "focus on Cloud" – but will having more cooks in the kitchen really help? Does anyone remember The Mythical Man-Month?
Secondly, and more fundamentally: Cloud may be a better software delivery model, but it delivers a standardized, one-size-fits-all product which for a significant minority is a worse overall experience, or cannot be used at all. It's like McDonalds vs. home cooking: eating out is certainly more convenient, but you can certainly eat better if you know how to cook, and some people with special dietary needs can't eat McDonalds food at all. The world would not be better off if the only food was take-away; likewise the industry trend to SaaS is not making user lives better.
Also, eating out every day gets really expensive. I'll tackle the issue of pricing in a separate post.
As painful as it is, perhaps Atlassian's announcement is for the best. Server development has been stagnant for many years. The rising frustration of customers can be seen on the open feature requests on https://jira.atlassian.com. Saying "we're not developing this any more" is more honest than continuing to take people's money without fulfilling the implicit promise to keep developing features.
Where to go from here? I don't rightly know yet. This is a perfect opportunity to evaluate the options, both SaaS, open source and hybrid ("open core"). I started a forum for Atlassian Server product refugees to evaluating options together, over at:
https://www.goodbyeserver.org/
Please join us and say hi, or at least subscribe to the newsletter.
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
I spend plenty of time poking around in Jira databases. Something that has always mildy annoyed me is the proliferation of the AO_ tables that plugins create:
redradish_jira=#
List of relations
┌────────┬─────────────────────────────────────────────┬──────────┬────────────────┐
│ Schema │ Name │ Type │ Owner │
├────────┼─────────────────────────────────────────────┼──────────┼────────────────┤
│ public │ AO_013613_ACTIVITY_SOURCE │ table │ redradish_jira │
│ public │ AO_013613_ACTIVITY_SOURCE_ID_seq │ sequence │ redradish_jira │
│ public │ AO_013613_EXPENSE │ table │ redradish_jira │
│ public │ AO_013613_EXPENSE_ID_seq │ sequence │ redradish_jira │
│ public │ AO_013613_EXP_CATEGORY │ table │ redradish_jira │
│ public │ AO_013613_EXP_CATEGORY_ID_seq │ sequence │ redradish_jira │
....
└────────┴─────────────────────────────────────────────┴──────────┴────────────────┘
(1318 rows)
Of those 1318 tables (!?), 1116 begin with AO_.
I know these AO_ tables are associated with plugins, but I have no idea (short of Google searching) which plugin generated which tables.
Furthermore every search involving these tables requires quoting the table name and column names, because they inexplicably needed to be uppercase.
To make life easier, I've create a project that automatically creates nicely named views on top of the AO tables:
https://github.com/redradishtech/activeobject_views
I can now see my Jira database contains tables from 56 plugins:
redradish_jira=# \dn
List of schemas
┌────────────────────┬────────────────┐
│ Name │ Owner │
├────────────────────┼────────────────┤
│ agile │ redradish_jira │
│ agilepoker │ redradish_jira │
│ api │ redradish_jira │
│ atlnotifications │ redradish_jira │
│ automation │ redradish_jira │
│ backbonesync │ redradish_jira │
│ betterpdf │ redradish_jira │
│ configmanagercore │ redradish_jira │
│ dvcs │ redradish_jira │
│ dynaforms │ redradish_jira │
│ groovy │ redradish_jira │
│ hipchat │ redradish_jira │
│ inform │ redradish_jira │
│ issueactionstodo │ redradish_jira │
│ jeditor │ redradish_jira │
│ jeti │ redradish_jira │
│ jiradevint │ redradish_jira │
│ jiradiagnostics │ redradish_jira │
│ jiraemailprocessor │ redradish_jira │
│ jirainvite │ redradish_jira │
│ jiramail │ redradish_jira │
│ jiramobile │ redradish_jira │
│ jiraoptimizer │ redradish_jira │
│ jiraprojects │ redradish_jira │
│ jiratranstrigger │ redradish_jira │
│ jirawebhooks │ redradish_jira │
│ jmcf │ redradish_jira │
│ jqlt │ redradish_jira │
│ jsd │ redradish_jira │
│ jsu │ redradish_jira │
│ kepler │ redradish_jira │
│ labelmanager │ redradish_jira │
│ navlinks │ redradish_jira │
│ portfolio │ redradish_jira │
│ portfolioteam │ redradish_jira │
│ projtemplates │ redradish_jira │
│ public │ postgres │
│ queries │ redradish_jira │
│ saml │ redradish_jira │
│ securelogin │ redradish_jira │
│ servicerocket │ redradish_jira │
│ sil │ redradish_jira │
│ simpletasklists │ redradish_jira │
│ simplifiedplanner │ redradish_jira │
│ startwork │ redradish_jira │
│ streams │ redradish_jira │
│ structure │ redradish_jira │
│ support │ redradish_jira │
│ tempo │ redradish_jira │
│ tempo2 │ redradish_jira │
│ tempoplanner │ redradish_jira │
│ timedpromise │ redradish_jira │
│ webhooks │ redradish_jira │
│ whitelist │ redradish_jira │
│ workhours │ redradish_jira │
│ xporter │ redradish_jira │
└────────────────────┴────────────────┘
(56 rows)
If I want to see tables for a specific plugin, I can limit psql to just the plugin's schema:
redradish_jira=# set search_path=tempo;
SET
redradish_jira=# \d
List of relations
┌────────┬─────────────────────┬──────┬────────────────┐
│ Schema │ Name │ Type │ Owner │
├────────┼─────────────────────┼──────┼────────────────┤
│ tempo │ account_v1 │ view │ redradish_jira │
│ tempo │ activity_source │ view │ redradish_jira │
│ tempo │ budget │ view │ redradish_jira │
│ tempo │ category_type │ view │ redradish_jira │
│ tempo │ category_v1 │ view │ redradish_jira │
│ tempo │ customer_permission │ view │ redradish_jira │
│ tempo │ customer_v1 │ view │ redradish_jira │
│ tempo │ exp_category │ view │ redradish_jira │
│ tempo │ expense │ view │ redradish_jira │
│ tempo │ favorites │ view │ redradish_jira │
│ tempo │ hd_scheme │ view │ redradish_jira │
│ tempo │ hd_scheme_day │ view │ redradish_jira │
│ tempo │ hd_scheme_member │ view │ redradish_jira │
│ tempo │ internal_issue │ view │ redradish_jira │
│ tempo │ link_v1 │ view │ redradish_jira │
│ tempo │ location │ view │ redradish_jira │
│ tempo │ membership │ view │ redradish_jira │
│ tempo │ permission_group │ view │ redradish_jira │
│ tempo │ pgp_group │ view │ redradish_jira │
│ tempo │ pgp_group_to_team │ view │ redradish_jira │
│ tempo │ pgp_group_v2 │ view │ redradish_jira │
│ tempo │ pgp_member │ view │ redradish_jira │
│ tempo │ pgp_member_v2 │ view │ redradish_jira │
│ tempo │ pgp_permission │ view │ redradish_jira │
│ tempo │ pgp_permission_v2 │ view │ redradish_jira │
│ tempo │ program │ view │ redradish_jira │
│ tempo │ project_config │ view │ redradish_jira │
│ tempo │ rate │ view │ redradish_jira │
│ tempo │ rate_table │ view │ redradish_jira │
│ tempo │ saved_report │ view │ redradish_jira │
│ tempo │ saved_report_v2 │ view │ redradish_jira │
│ tempo │ team │ view │ redradish_jira │
│ tempo │ team_link │ view │ redradish_jira │
│ tempo │ team_member │ view │ redradish_jira │
│ tempo │ team_member_v2 │ view │ redradish_jira │
│ tempo │ team_permission │ view │ redradish_jira │
│ tempo │ team_role │ view │ redradish_jira │
│ tempo │ team_to_member │ view │ redradish_jira │
│ tempo │ team_v2 │ view │ redradish_jira │
│ tempo │ user_index │ view │ redradish_jira │
│ tempo │ user_location │ view │ redradish_jira │
│ tempo │ wa_sl_value │ view │ redradish_jira │
│ tempo │ wa_value │ view │ redradish_jira │
│ tempo │ wl_scheme │ view │ redradish_jira │
│ tempo │ wl_scheme_day │ view │ redradish_jira │
│ tempo │ wl_scheme_member │ view │ redradish_jira │
│ tempo │ work_attribute │ view │ redradish_jira │
└────────┴─────────────────────┴──────┴────────────────┘
(47 rows)
I hope this helps fellow SQL hackers out there!
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
TLSv1.3 is relatively new and shiny, as fundamental web protocols go, and TLS stacks are still working out the bugs. In my experience:
- Back in April I had a client whose Jira connections to Slack would hang soon after server start.
This turned out to be caused by a TLS 1.3 bug in Java 11. Jira loses track of the TCP connection state (leaving the TCP connection in CLOSE-WAIT forever) and blocks, thereby blocking the whole webhook thread pool:https://jira.atlassian.com/browse/JRASERVER-70780
https://jira.atlassian.com/browse/JRASERVER-70189
This was triggered by some change on Slack's end. Perhaps Slack switched their default from TLS 1.2 to 1.3 when they removed older TLS versions the previous month. Same client, 4 months later, suddenly experienced complete failure of Crowd to authenticate users against their LDAP.
The relevant line in the stacktrace is:Caused by: org.springframework.ldap.CommunicationException: ldap.phx7.<redacted>.com:636; nested exception is javax.naming.CommunicationException: ldap.phx7.<redacted>.com:636 [Root exception is javax.net.ssl.SSLHandshakeException: extension (5) should not be presented in certificate_request]
Once again some hurried Googling suggested this is a TLSv1.3 problem.
In both cases the solution was to avoid TLSv1.3 for now, by setting the Java flag:
-Djdk.tls.client.protocols=TLSv1.2
The first bug might also be avoidable by upgrading to Java 11.0.8 or higher. I haven't tested that yet though.
For now, I'm setting that flag in all instances I administer, until TLS servers and clients get their act together.
An eventful day. Besides upgrading Jira and Confluence, I also do upgrades of the underlying Ubuntu operating system. Today I had 8 AWS EC2 instances to upgrade, all running Ubuntu 16.04.6 LTS.
I did the usual steps, upgrading the sandboxes first:
apt-get update
apt-get upgrade
reboot
3 of the 4 sandboxes failed to boot! They were all stuck on Grub rescue screen, showing:
Booting from Hard Disk 0...
error: symbol `grub_calloc' not found. Entering rescue mode...
grub rescue> _
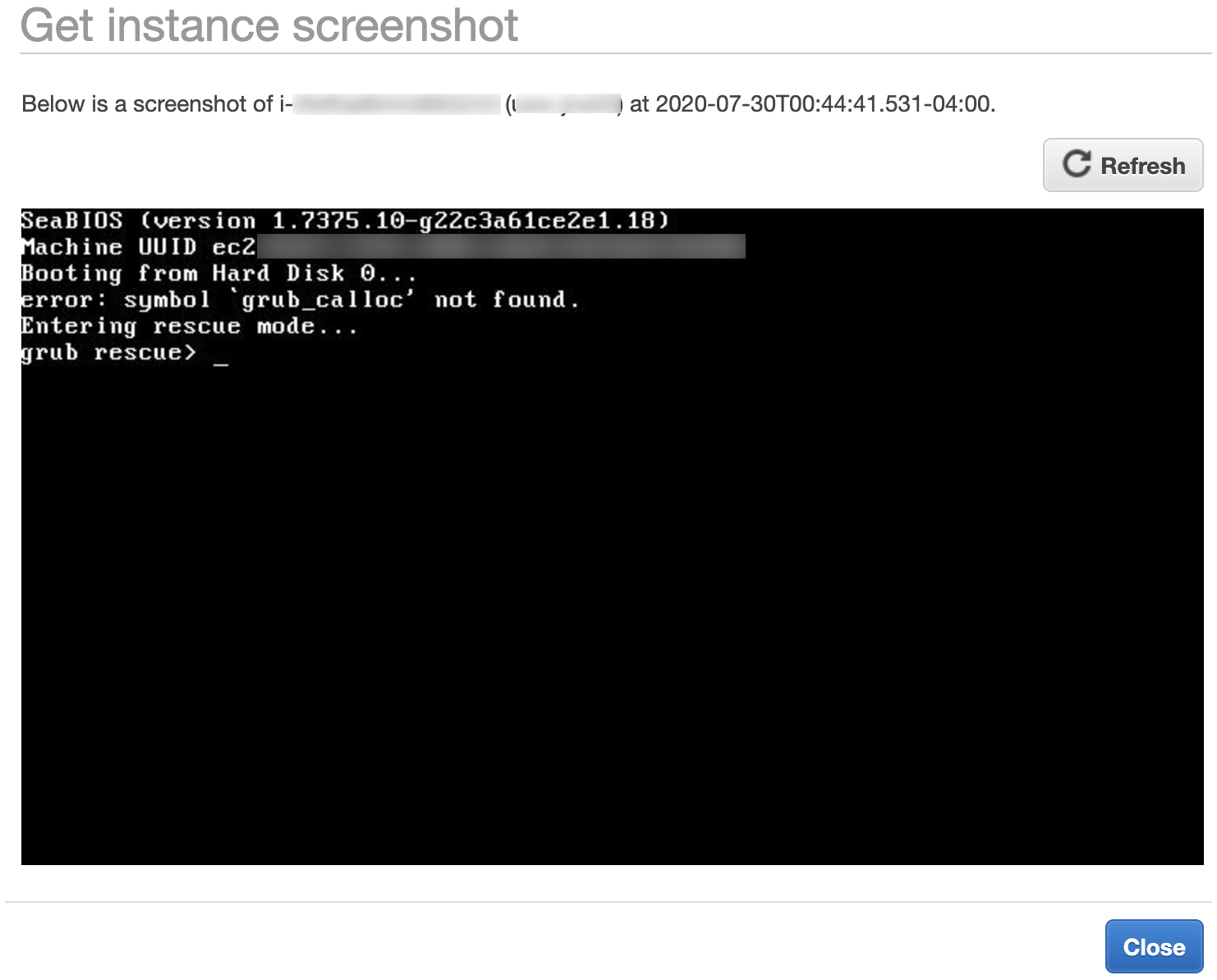
Googling yielded this askubuntu.com post, which provides a general way forward: we need to reinstall grub with grub-install <disk> .
How to reinstall grub on AWS
The joyous thing about AWS is you only get a screenshot of the grub rescue> prompt. You can't actually rescue anything. (Edit: this wasn't a MacGuyver-rescue'able situation anyway.)
For AWS the process is:
- Launch a recovery t2.micro in the same AZ/subnet as your borked instance(s).
- Stop the broken instance and detach the root volume (the one containing the OS).
- Attach the root volume to the recovery instance as /dev/sdf:
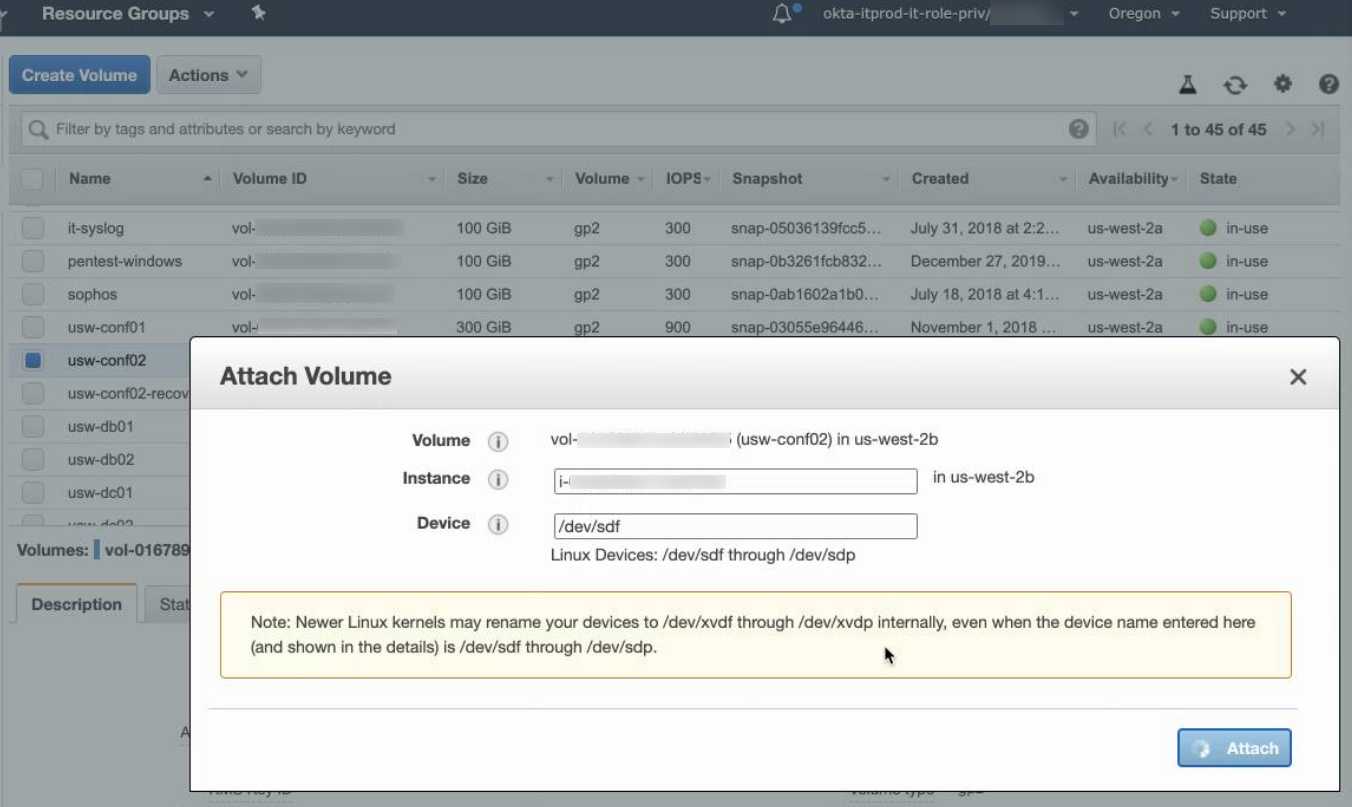
Now run these commands:
mount /dev/xvdf1 /mnt for fs in {proc,sys,tmp,dev}; do mount -o bind /$fs /mnt/$fs; done chroot /mnt lsblk grub-install /dev/xvdfIt looked like this:
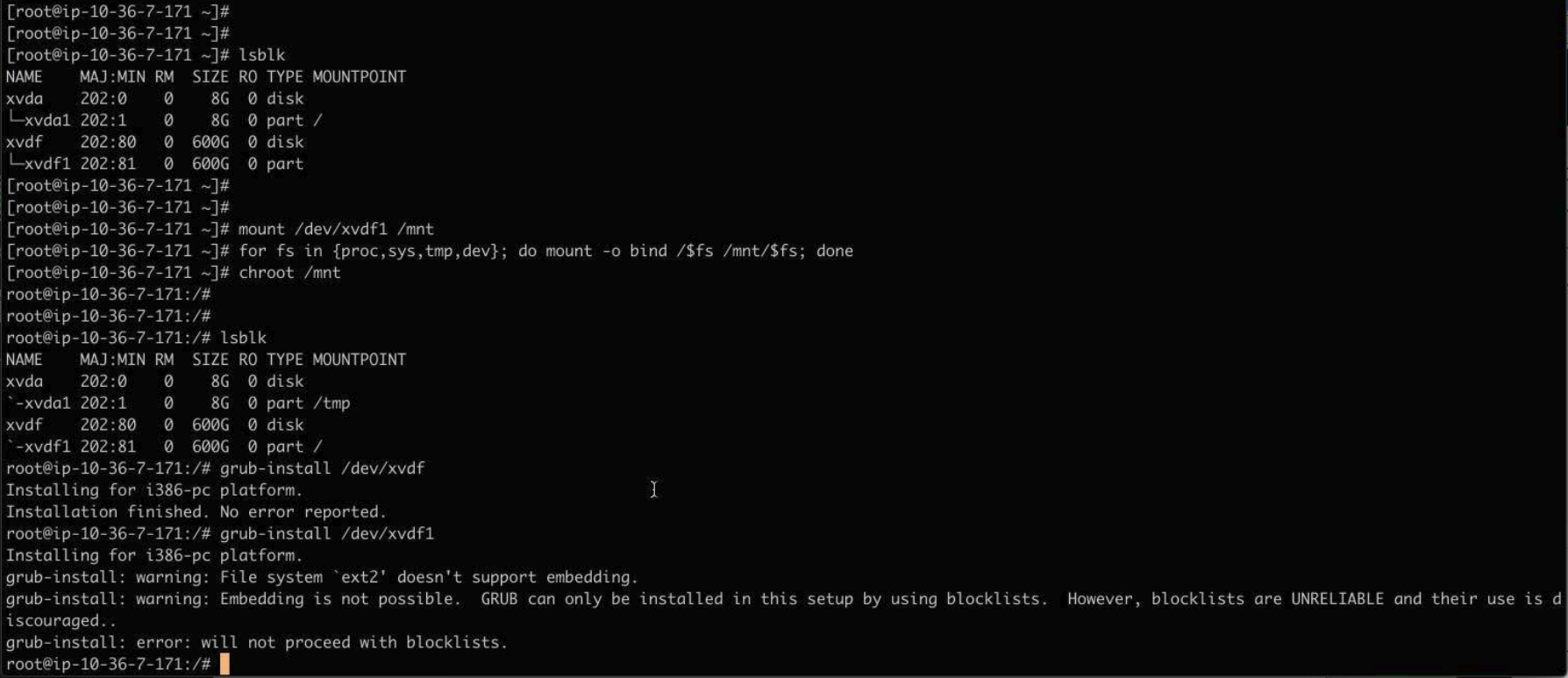
Then:
exit for fs in {proc,sys,tmp,dev}; do umount /mnt/$fs; done umount /mnt(Edit: added fs umounts per this LP comment)
- Detach the volume from the recovery instance
- Attach the volume back on the original instance.
- Reboot original instance
Then you're golden.
What caused the problem?
Edit: rewritten 31/July based on lp#1889509 comments)
On the 3 servers that broke, apt-get update did not prompt me for anything grub-related. Checking afterwards with debconf-get-selections I see that debconf was pre-configured to install grub on one device:
grub-pc grub-pc/install_devices_disks_changed multiselect /dev/disk/by-id/nvme-Amazon_Elastic_Block_Store_vol01e713272eb256s52-part1
That device symlink is wrong. It was either pre-seeded by cloud-init or by the AMI creator (I'm not sure). My servers need grub on /dev/xvdf, not /dev/xvdf1 . The grub postinst script would have encountered the same failure I saw while recovering:
# grub-install /dev/xvdf1 grub-install: warning: File system `ext2` doesn't support embedding. grub-install: warning: Embedding is not possible. GRUB can only be installed in this setup by using blocklists. However, blocklists are UNRELIABLE and their use is discouraged.. grub-install: error: will not proceed with blockists.
I must not have noticed this error in the wall of text scrolling past on the upgrade.
Grub should have failed hard, but didn't (now been filed as https://bugs.launchpad.net/ubuntu/+source/grub2/+bug/1889556/ ).
The result: grub is upgraded in my /boot partition, but the grub loader in /dev/xvdb is still old, and the mismatch causes the failure (hat tip to ~juliank on lp#1889509).
To reinforce this theory, we turn to 1 of the 4 sandboxes did not break. When I did apt-get upgrade the surviving server had previously demanded I give it some 'GRUB install devices':
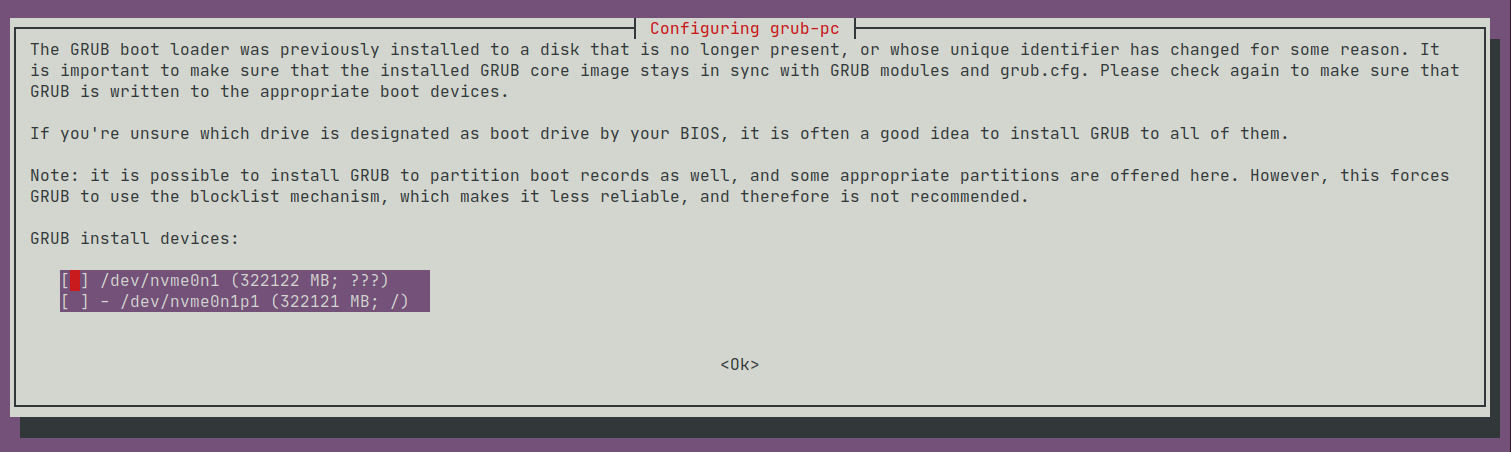
I had decided to take debconf's advice, and installed grub on all devices:
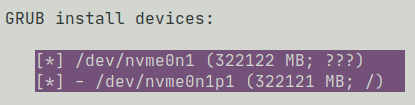
and that saved me, at least on this one server.
But why did this update go wrong?
I upgrade OS packages on these servers every month, but looking at my /var/log/dpkg.log history, grub is very rarely updated. The last update was a full year ago:
root@usw-jira01:/var/log# zgrep 'upgrade grub-pc:amd64' dpkg.log* dpkg.log:2020-07-30 04:06:23 upgrade grub-pc:amd64 2.02~beta2-36ubuntu3.23 2.02~beta2-36ubuntu3.26 dpkg.log.12.gz:2019-07-15 02:04:55 upgrade grub-pc:amd64 2.02~beta2-36ubuntu3.20 2.02~beta2-36ubuntu3.22 dpkg.log.7.gz:2019-12-09 03:06:58 upgrade grub-pc:amd64 2.02~beta2-36ubuntu3.22 2.02~beta2-36ubuntu3.23
So I posit that there is nothing directly wrong with this grub update specifically, but rather I (and a lot of other people) are hitting a problem in the general Debian grub update process; specifically, when grub fails to update with an error:
grub-install: warning: File system `ext2` doesn't support embedding.
grub-install: warning: Embedding is not possible. GRUB can only be installed in this setup by using blocklists. However, blocklists are UNRELIABLE and their use is discouraged..
grub-install: error: will not proceed with blockists
it should fail hard, but instead proceeds.
How do I know if my server will break?
If your system boots with UEFI, you're fine.
If you're on Linode with default settings, you're fine.
For BIOS users, including AWS and other VPS hosters, run the following:
cd /tmp curl -LOJ https://gist.github.com/jefft/76cf6c5f6605eee55df6079223d8ba1c/raw/bf0985bdb1e2ef5fc74e2aee7ebf29c4eaf7199f/grubvalidator.sh chmod +x grubvalidator.sh ./grubvalidator.sh
This script checks if your grub version includes a fix for lp #1889556 and if not, checks if you are likely to experience boot problems.
Edit: I filed a launchpad bug: https://bugs.launchpad.net/ubuntu/+source/grub2/+bug/1889509
Edit: The essential problem is that the grub-pc package doesn't fail in the presence of bad debconf data. That has been fixed per https://bugs.launchpad.net/ubuntu/+source/grub2/+bug/1889556.
Edit2: Updated 'What caused the problem' section with info from comments on the bug.
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
A suprising log I noticed on JIRA startup today:
2020-07-11 14:18:29,465+1000 JIRA-Bootstrap ERROR [c.k.j.p.keplercf.admin.KCFLauncher] Cannot copy the JSP. Error was:java.io.FileNotFoundException: /opt/atlassian/redradish_jira/8.10.0/atlassian-jira/secure/popups/ksil_userpicker.jsp (Permission denied)
java.io.FileNotFoundException: /opt/atlassian/redradish_jira/8.10.0/atlassian-jira/secure/popups/ksil_userpicker.jsp (Permission denied)
at java.base/java.io.FileOutputStream.open0(Native Method)
at java.base/java.io.FileOutputStream.open(FileOutputStream.java:298)
at java.base/java.io.FileOutputStream.<init>(FileOutputStream.java:237)
at java.base/java.io.FileOutputStream.<init>(FileOutputStream.java:187)
at com.keplerrominfo.jira.plugins.keplercf.admin.KCFLauncher.copyJSPFile(KCFLauncher.java:346)
at com.keplerrominfo.jira.plugins.keplercf.admin.KCFLauncher.launch(KCFLauncher.java:188)
at com.keplerrominfo.refapp.launcher.AbstractDependentPluginLauncher.tryToLaunch(AbstractDependentPluginLauncher.java:139)
at com.keplerrominfo.refapp.launcher.AbstractDependentPluginLauncher.handleEvent(AbstractDependentPluginLauncher.java:85)
at com.keplerrominfo.jira.plugins.keplercf.admin.KCFLauncher.onPluginEvent(KCFLauncher.java:215)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at com.atlassian.event.internal.SingleParameterMethodListenerInvoker.invoke(SingleParameterMethodListenerInvoker.java:42)
at com.atlassian.event.internal.AsynchronousAbleEventDispatcher.lambda$null$0(AsynchronousAbleEventDispatcher.java:37)
at com.atlassian.event.internal.AsynchronousAbleEventDispatcher.dispatch(AsynchronousAbleEventDispatcher.java:85)
at com.atlassian.event.internal.LockFreeEventPublisher$Publisher.dispatch(LockFreeEventPublisher.java:220)
at com.atlassian.event.internal.LockFreeEventPublisher.publish(LockFreeEventPublisher.java:96)
...
2020-07-11 12:26:36,465+1000 UpmAsynchronousTaskManager:thread-2 ERROR jturner 736x198x1 1uhj4pl 127.0.0.1 /rest/plugins/1.0/updates/all [c.k.j.p.keplercf.admin.KCFLauncher] You must manually copy the ksil_userpicker.jsp file into the correct directory (read the manual). Destination path: JIRA-HOME/atlassian-jira/secure/popups/ksil_userpicker.jsp
It appears this is caused by the SIL Engine plugin:

SIL Engine is attempting to copy a JSP to JIRA's app directory, and failing due to permissions.
SIL Engine is a "library plugin", a dependency of other CPrime plugins, which I had experimented with in the past (Power Custom Fields, I think). The problem with "library plugins" is that they hang around even after the last plugin that used them is uninstalled. Thus; SIL Engine on my system.
Digression: Permissions in your /opt/atlassian/jira directory
The attempted copy failed ('Permission Denied'), and rightly so. JIRA (and any webapp) should absolutely not be allowed to write to its own installation directory. Back in 2009 I had not learned this. I was a volunteer administrator of https://jira.apache.org, and left the app directory writable, which contributed to the server being hacked:

Countless PHP hacks have been enabled to not following this rule, due to apps like Wordpress encouraging the anti-pattern of allowing the app to upgrade itself.
But what about ksil_userpicker.jsp?
There is nothing on the web about ksil_userpicker.jsp, so I contacted CPrime. Developer Radu Dumitriu replied:
That file was necessary because, at the time, Jira didn't have the ability to let us create a user picker panel (3.x). That's the solution we came with, so obviously it remained unchanged. We will change that when we'll publish a major version of the addon (hopefully).
So the answer to both your questions is 'history'
So it looks innocuous. Still, I think it best to ignore the error until usage actually demands this JSP's presence. If, like for me, SIL Engine is a relic, you would be best off uninstalling it.
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
As of Tempo 10.19.0 this problem is fixed.See edit inline.
Tempo has a Team custom field. Here it is rendered in the Issue Navigator:
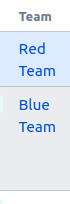
Sadly, if you view Team in CSV you get:

And likewise the view in the Excel-like Issue Editor plugin:
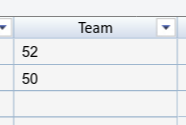
I have reported this as a bug to Tempo (10.17.x) but it's basically "Won't Fix". The field's native representation (i.e. issue.getCustomFieldValue() ) is a String like "52".
Edit: This is now fixed. In Tempo 10.18 and earlier, issue.getCustomFieldValue() returned a String like "52". In Tempo 10.19+ you now get a com.tempoplugin.team.api.TeamImpl object back, whose toString() returns the team name.
While that fixes the CSV export, for me it doesn't fix 'Issue Editor' values, which are still numbers. Perhaps I am just experiencing caching or some sort, or perhaps the Issue Editor plugin is doing something else weird. I'll update as I discover more.
Fortunately we have ScriptRunner. Here is source for a Script Field called Tempo Team Name which renders the actual team name:
/**
* 'Tempo Team Name' script Field that renders the issue's Tempo Team name, if any.
* The plain tempo 'Team' field renders as an integer in CSV and Issue Editor views.
* Use this field instead to render the team name.
*
* https://www.redradishtech.com/pages/viewpage.action?pageId=24641537
* jeff@redradishtech.com, 23/Jul/20
*/
import com.atlassian.jira.component.ComponentAccessor
import com.atlassian.jira.issue.fields.CustomField
import com.onresolve.scriptrunner.runner.customisers.PluginModule
import com.onresolve.scriptrunner.runner.customisers.WithPlugin
def customFieldManager = ComponentAccessor.customFieldManager
def teamField = customFieldManager.getCustomFieldObjects(issue).find { it.name == "Team" }
if (!teamField) return;
def team = issue.getCustomFieldValue(teamField)
if (!team) return;
@WithPlugin("com.tempoplugin.tempo-teams")
import com.tempoplugin.team.api.TeamManager
import groovy.transform.Field
import com.onresolve.scriptrunner.runner.ScriptRunnerImpl
@Field TeamManager teamManager
teamManager = ScriptRunnerImpl.getPluginComponent(TeamManager)
teamManager.getTeamName(team)
Here it is:
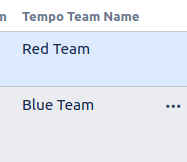
This field can now be used in CSV and Issue Editor views to see the team names.
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
Does your company use Tempo Timesheets? Do you use it for getting summaries of people's work hours across projects? If so, here is a nasty gotcha: it's possible your timesheet reports are not getting hours for all projects.
When Tempo Timesheets is installed, it introduces a new project permission, called View All Worklogs (Tempo docs). Despite its generic name, this permission does not hide worklogs in general. Hiding the Work Logs tab is something only Atlassian could do, and given the age of this ticket - JRASERVER-2364 - Getting issue details... STATUS - it isn't likely to happen.
No, the View All Worklogs permission only restricts users' ability to view worklogs within Tempo.
So let's say our worker Sally has logged work on issues in projects A to Z. Sally's manager now wants to see the monthly timesheet. However unbeknownst to anyone, project C's permission scheme contains:

and Sally's manager is not a member of 'Tempo Project Manager' for project C.
The timesheet will look correct, having hourly figures pulled from projects A,B, D....Z. It will just silently not count totals from project C.
Who would ever notice such a discrepancy, especially when, after checking, Sally's worklogs on project C are visible to Sally's manager in the Worklogs tab?
So in short, the View All Worklogs permission is a giant footgun, particularly when used with Project roles. If you rely on your Tempo reports, I suggest double-checking permission schemes to ensure you're not accidentally missing worklogs.
(actually, it was only by comparing Tempo totals with the equivalent SQL-based Monthly Timesheets Report that my my client discovered this)
Today I booted up my personal Confluence as usual, to find the header mysteriously broken:

The error in black-on-blue is:
$soyTemplateRendererHelper.getRenderedTemplateHtml("com.atlassian.auiplugin:aui-experimental-soy-templates", "aui.page.header.soy", $templateParameters)
Nothing unusual in the logs.
The fix
After the usual futzing around, I found this KB article describing a similar problem. In the UPM plugin (the URL is /plugins/servlet/upm?source=side_nav_manage_addons by the way) under the 'System' plugins, there is indeed one module disabled:
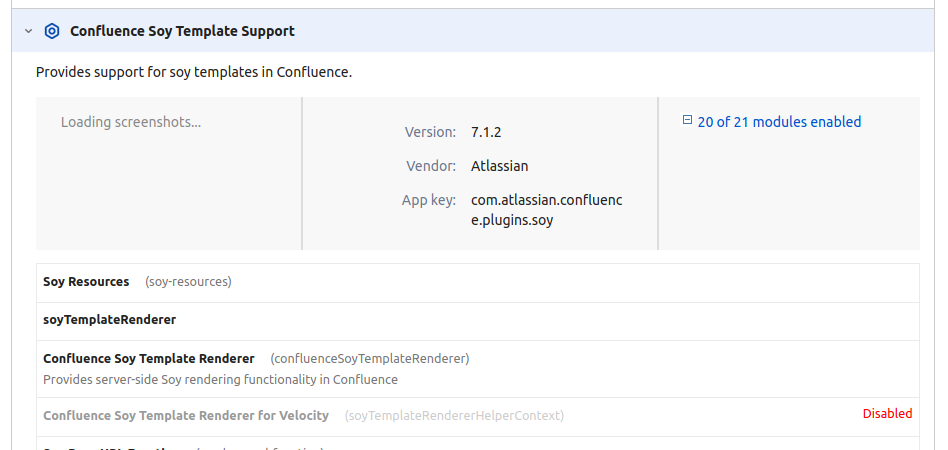
The SQL fix from the KB article worked:
UPDATE BANDANA SET BANDANAVALUE='<map/>' WHERE BANDANAKEY='plugin.manager.state.Map'
If I ever find out why this happens I'll update this post.
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
Today's project: create a Confluence report that shows hours logged for all users in a given month. Let the user specify the year/month in question, and optionally filter the set of reported users:
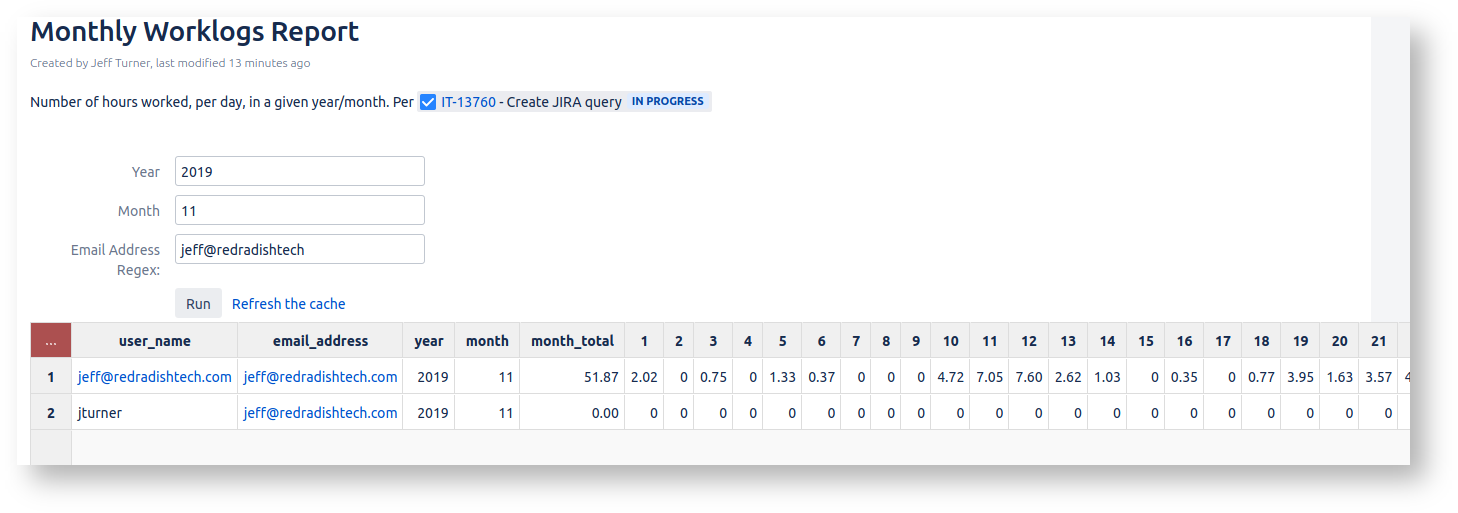
This report shows hours for all users even if they haven't logged any this month, which is something Tempo's reports can't do.
Implementation
I have expanded on the implementation in a KB article, Creating interactive Jira reports in Confluence using free tools
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
Just a notice that I will be gradually moving my open source repositories from Bitbucket (http://bitbucket.org/redradish) to Github (https://github.com/redradishtech).
Github has always been faster and nicer, with better network effects. I've stuck with Bitbucket until now for its Mercurial support. With the abrupt termination of Mercurial support I have no further reason to stay. My non-public code will live https://meta.sr.ht/
This page constitutes random notes from my work day as an Atlassian product consultant, put up in the vague hope they might benefit others. Expect rambling, reference to unsolved problems, and plenty of stacktraces. Check the date as any information given is likely to be stale.
Sending email via Postfix
I generally like to configure Jira and Confluence to send outgoing emails to localhost , and there have Postfix do the final mail delivery:
Delegating to Postfix has at least three benefits:
- It keeps sensitive SMTP credentials out of Jira
- I can configure Postfix on staging to 'blackhole' all outgoing emails (i.e. send them to a local file), so when production Jira data is run on staging, there's no chance of staging accidentally emailing people even if I forgot to set
-Datlassian.mail.senddisabled=true - It gets emails out of Jira's "useless" (to quote Jira's tech lead) mail queue as fast as possible, into a competently designed MTA that actually persists emails across restarts and handles retries to overcome transient errors.
Postfix's message size limit
One caveat I discovered today: Postfix will reject emails larger than a certain size (the message_size_limit parameter), including emails from Jira. If you have JETI installed, and users use JETI to email issues with their attachments, then it's quite easy for Jira to be sending JETI emails over 10Mb. Postfix rejects them, and they end up in the Jira error queue, where they languish forever until Jira is restarted, whereupon they are lost (did I mention "useless"?).
So if you don't want to lose your outgoing JETI emails, increase Postfix's message_size_limit to whatever you're comfortable sending. In /etc/postfix/main.cf:
# Increase the maximum email size from 10Mb to 50Mb. https://www.redradishtech.com/x/JoAjAQ message_size_limit = 50240000
Then sudo postfix reload
SMTP timeouts
Following increasing the message_size_limit , I noticed a SocketTimeoutExceptions in your atlassian-jira-outgoing-mail.log:
2019-12-17 22:11:08,828 ERROR [] Sending mailitem To='user@example.com' Subject='Issue Updated: (IT-183421) Sample ticket' From='null' FromName='Jeff Turner (Jira)' Cc='' Bcc='' ReplyTo='null' InReplyTo='<JIRA.502599.1572547564000@Atlassian.JIRA>' MimeType='text/html' Encoding='UTF-8' Multipart='javax.mail.internet.MimeMultipart@3fb8818d' MessageId='JIRA.502599.1572547564000.10326.1576446859026@Atlassian.JIRA' ExcludeSubjectPrefix=false' jeff@redradishtech.com 1330x2600246x1 svwdbg 63.80.172.147 /secure/admin/MailQueueAdmin.jspa Error occurred in sending e-mail: To='user@example.com' Subject='Issue Updated: (IT-183421) Sample ticket' From='null' FromName='Jeff Turner (Jira)' Cc='' Bcc='' ReplyTo='null' InReplyTo='<JIRA.502599.1572547564000@Atlassian.JIRA>' MimeType='text/html' Encoding='UTF-8' Multipart='javax.mail.internet.MimeMultipart@3fb8818d' MessageId='JIRA.502599.1572547564000.10326.1576446859026@Atlassian.JIRA' ExcludeSubjectPrefix=false'
com.atlassian.mail.MailException: javax.mail.MessagingException: Exception reading response;
nested exception is:
java.net.SocketTimeoutException: Read timed out
at com.atlassian.mail.server.impl.SMTPMailServerImpl.sendWithMessageId(SMTPMailServerImpl.java:222) [atlassian-mail-5.0.0.jar:?]
at com.atlassian.mail.queue.SingleMailQueueItem.send(SingleMailQueueItem.java:44) [atlassian-mail-5.0.0.jar:?]
...
Caused by: javax.mail.MessagingException: Exception reading response;
nested exception is:
java.net.SocketTimeoutException: Read timed out
at com.sun.mail.smtp.SMTPTransport.readServerResponse(SMTPTransport.java:2445) [javax.mail-1.6.0.jar:1.6.0]
at com.sun.mail.smtp.SMTPTransport.issueSendCommand(SMTPTransport.java:2322) [javax.mail-1.6.0.jar:1.6.0]
at com.sun.mail.smtp.SMTPTransport.finishData(SMTPTransport.java:2095) [javax.mail-1.6.0.jar:1.6.0]
at com.sun.mail.smtp.SMTPTransport.sendMessage(SMTPTransport.java:1301) [javax.mail-1.6.0.jar:1.6.0]
at com.atlassian.mail.server.impl.SMTPMailServerImpl.sendMimeMessage(SMTPMailServerImpl.java:242) [atlassian-mail-5.0.0.jar:?]
at com.atlassian.mail.server.managers.EventAwareSMTPMailServer.sendMimeMessage(EventAwareSMTPMailServer.java:25) [classes/:?]
at com.atlassian.mail.server.impl.SMTPMailServerImpl.sendWithMessageId(SMTPMailServerImpl.java:184) [atlassian-mail-5.0.0.jar:?]
... 297 more
Caused by: java.net.SocketTimeoutException: Read timed out
at java.base/java.net.SocketInputStream.socketRead0(Native Method) [?:?]
at java.base/java.net.SocketInputStream.socketRead(SocketInputStream.java:115) [?:?]
at java.base/java.net.SocketInputStream.read(SocketInputStream.java:168) [?:?]
at java.base/java.net.SocketInputStream.read(SocketInputStream.java:140) [?:?]
at com.sun.mail.util.TraceInputStream.read(TraceInputStream.java:126) [javax.mail-1.6.0.jar:1.6.0]
at java.base/java.io.BufferedInputStream.fill(BufferedInputStream.java:252) [?:?]
at java.base/java.io.BufferedInputStream.read(BufferedInputStream.java:271) [?:?]
at com.sun.mail.util.LineInputStream.readLine(LineInputStream.java:104) [javax.mail-1.6.0.jar:1.6.0]
at com.sun.mail.smtp.SMTPTransport.readServerResponse(SMTPTransport.java:2425) [javax.mail-1.6.0.jar:1.6.0]
... 303 more
The notification in the error queue was still there, but Postfix indicated that it had received and forwarded on the email!
Jira has a Timeout setting for SMTP servers in the Outgoing Mail section, and the default value is 10 seconds. From the stacktrace, it appears Jira opened a SMTP connection to Postgres, sent the large email (in my case, 23Mb), and then timed out waiting for a response from Postgres. Postgres considered the delivery a success, while Jira considered it a failure, and left the email in the error queue. Clicking 'Resend error queue' results in the same email being sent again.
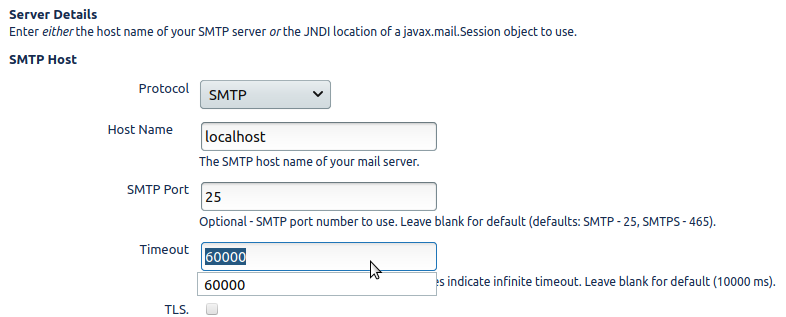
The fix for this is to increase Jira's SMTP timeout, which can be done in the SMTP Mail Server settings under Outgoing Mail. On the principle of avoiding Jira's error queue at all costs, this timeout should be set to something large - anything less than 1 minute, which is the queue flush frequency:
The Confluence Numbered Headings plugin is one of those plugins that was free for many years, then went commercial.
Until recently it still worked, but not any more. As of Confluence 7.1 and later the UPM flags the old version as incompatible:
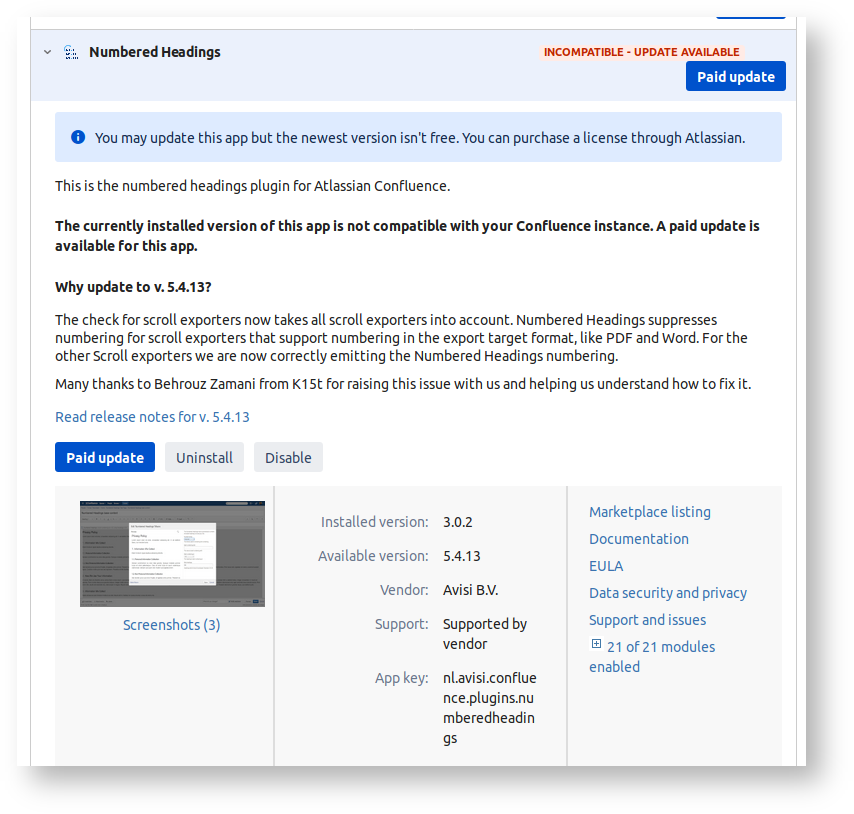
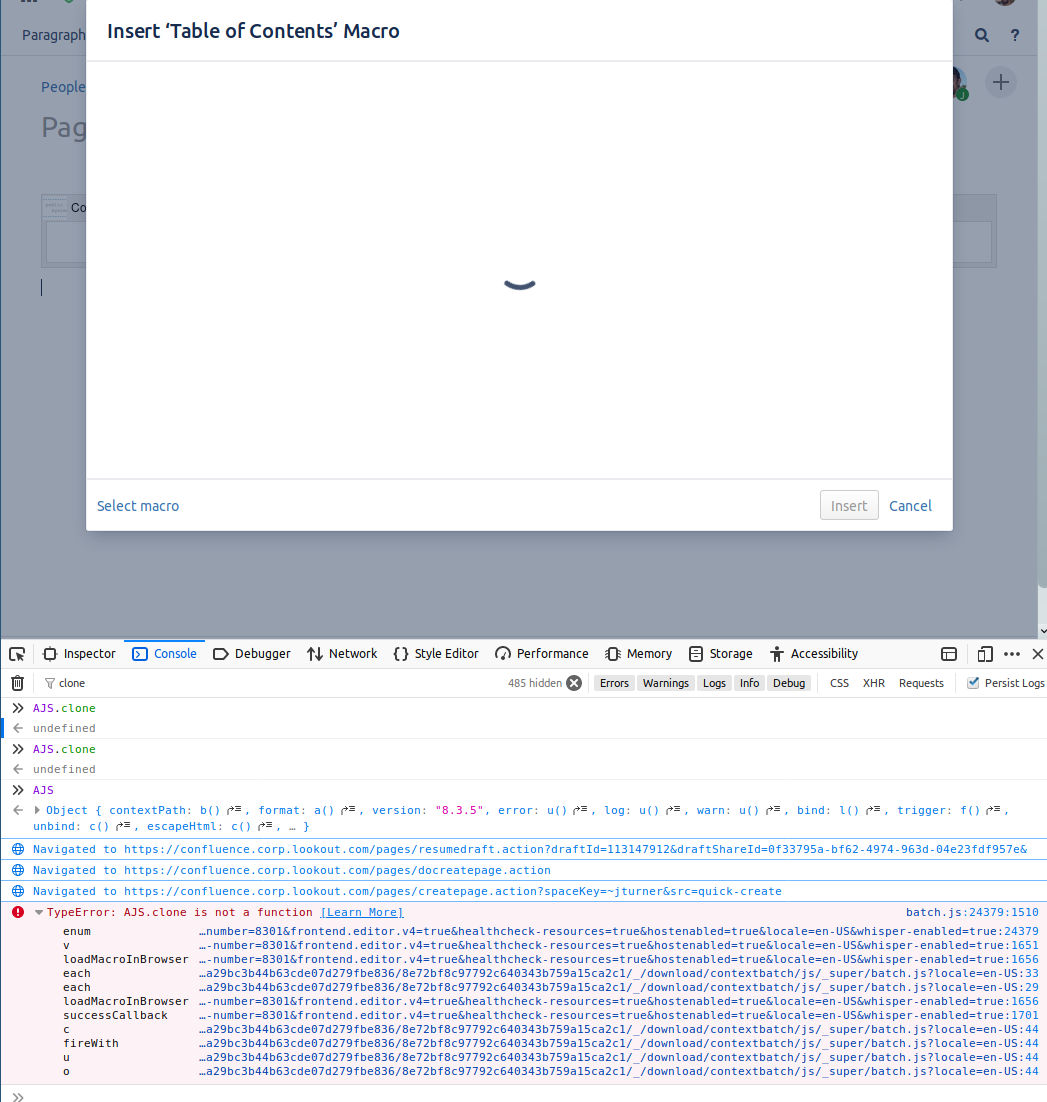
The effect of this incompatibility is subtle: Numbered Headings works fine just as before, but now if you try to insert any macro that has a body using '+' icon, you get an endless spinner, and a Javascript AJS.clone is not a function error:
The good news is that after upgrading, the plugin is still free: it just as a 'Pro' version:
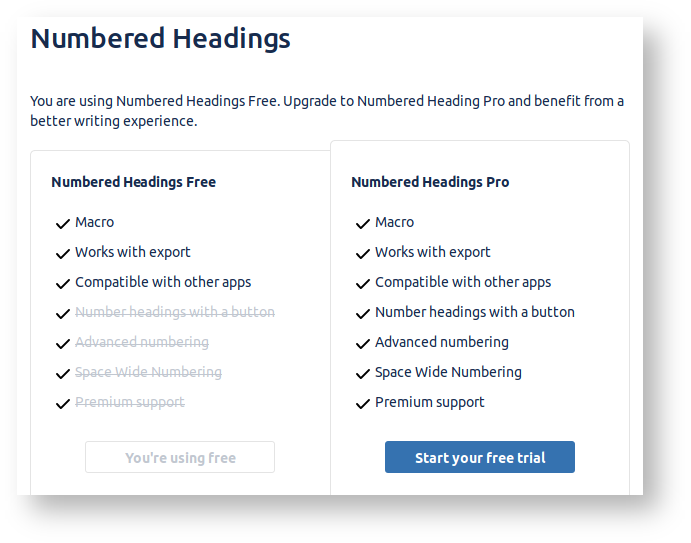
So upgrade away, and if your budget permits, support the plugin authors by paying for the Pro version.